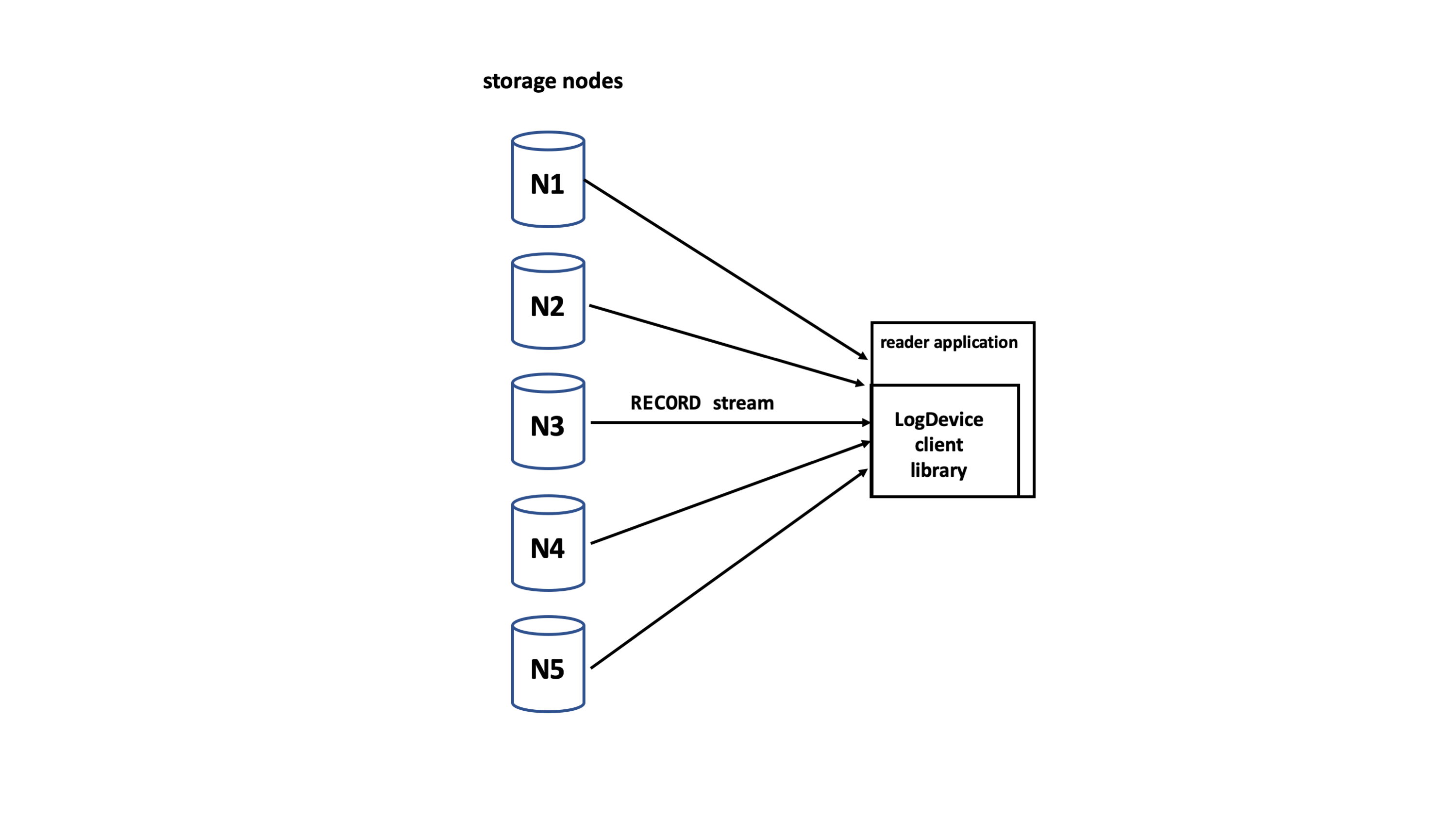
Read path
One of the design principles for LogDevice is to maximize record placement options so as to increase write availability and handle spikes in the write rate. LogDevice uses non-deterministic record placement: each individual record may potentially be stored on any storage node in the cluster.
All of these placement options optimize for writing, but they complicate the read path for LogDevice. Client readers need to efficiently find and obtain the copies, and then deliver the records to the application in the correct order.
Both read availability and efficiency are important to LogDevice. Let's discuss how reads work, and how we make sure data is delivered reliably and efficiently.
This page has a number of topics:
- Overview — a review of a few of the components involved in the read path.
- How reads happen — how the client reads records.
- Gap detection — what happens if the sequence numbers of the records are not continuous.
- Optimizations — ways to make reads faster.
Overview
LogDevice client readers connect directly to the storage nodes. Records are sent from the storage node to the client in stateful streams.
Read API
Although the client itself is complex, the API that you use to read records in sequential streams from your application is fairly straightforward.
- startReading (log id, from log sequence number (LSN), until LSN = MAX) — non-prescriptive reading
- read (count, records_out, gap_out) — records_out vector, gap_out vector is returned
You can learn more about how to use the reading API here.
Copyset
The copyset is the set of storage nodes on which the copies of a particular record are stored. The copyset for each record is included in the header along with the log id, LSN, and timestamp when the record is written.
The copyset may be mutated:
- By the sequencer at write time, if a node fails to write a record.
- By the rebuilding process.
Metadata log
Every log has an associated metadata log that contains the history of all epochs and their associated metadata for the log. While the epoch store contains only the current nodeset and replication properties for a log, the metadata log contains ranges of epochs, and for each range, the nodeset and the replication factor. The metadata log is small and only changes when the nodeset or replication properties are updated, which doesn't happen very often. Metadata logs are kept on storage nodes, and are replicated and otherwise treated as regular logs.
How reads happen
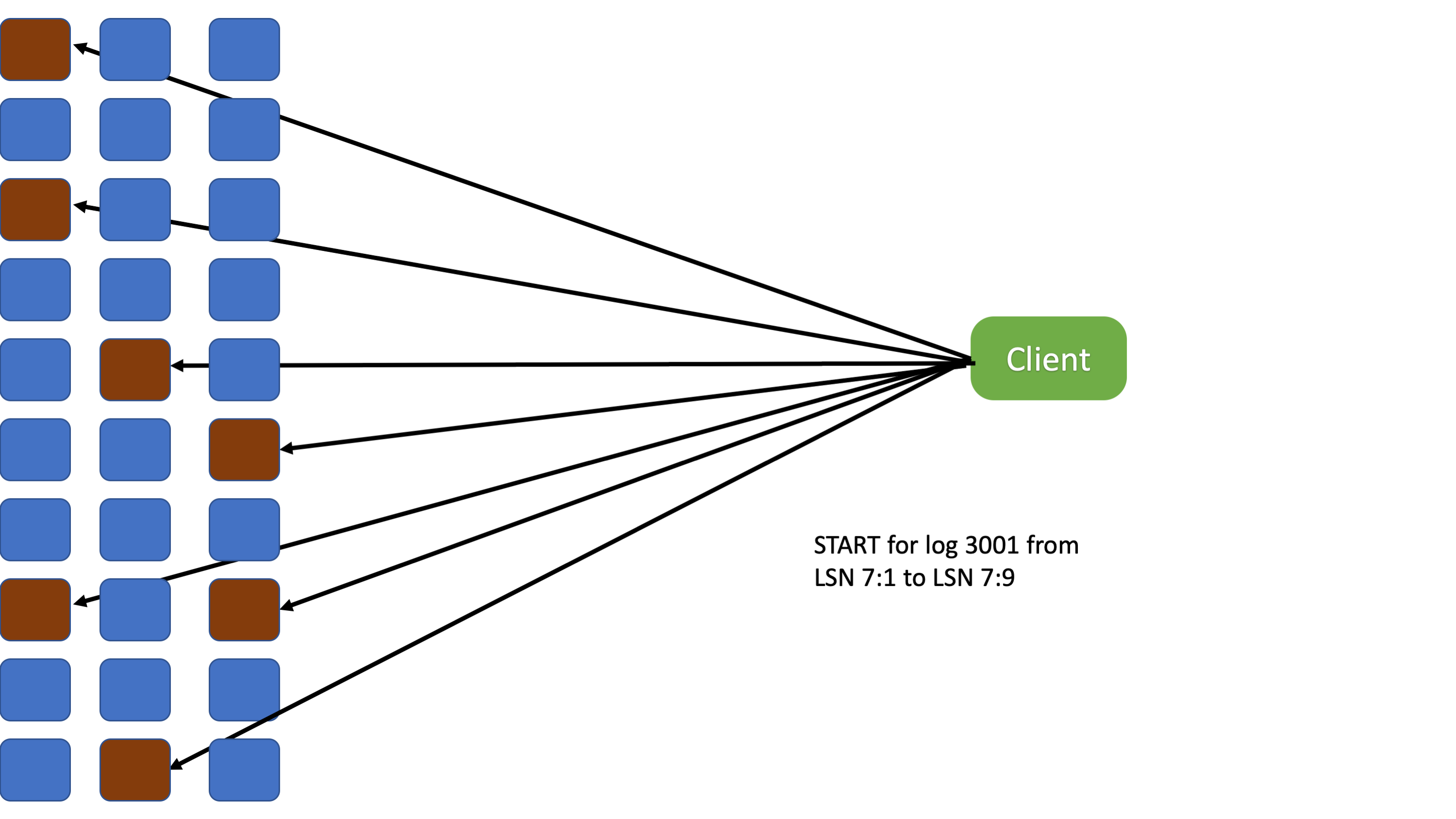
The client reader gets the nodeset, which is the set of storage nodes that contain the data, and the replication property of the log from the metadata log. It opens a socket to each of the nodes and initiates a streaming protocol by sending it the start and until sequence numbers it wishes to read. Usually all of those nodes have records to deliver.
As discussed in Write path, storage nodes only deliver records that have been released by the sequencer, i.e., those with LSNs less than or equal to the release pointer.
Each server starts sending the records they have for the requested log ids. There is an implicit guarantee that each node sends its records in order.
The client adds the records that it receives from the storage nodes to a buffer of configurable size. The buffer is used as a sliding window for these purposes:
- Flow control. Each slot represents a sequence number of a record that the client is waiting for. As the client receives the records, the window is slid. The client sends updates to the storage nodes with the new boundaries of the window so that they send more records.
- Re-ordering. Because storage nodes send records at different paces, the reader may receive them out of order. If the first record received is for the second row of the buffer, the reader does not deliver it to the application. Instead, it waits for the record for the first row. When that arrives, both the record for the first and second row are delivered and the buffer is rotated so that the third row becomes the next record to deliver.
- De-duplication. When Single-Copy-Delivery (SCD) is not active, all copies of each record are sent to the client reader. The reader drops copies that it already has. More on SCD in a later section.
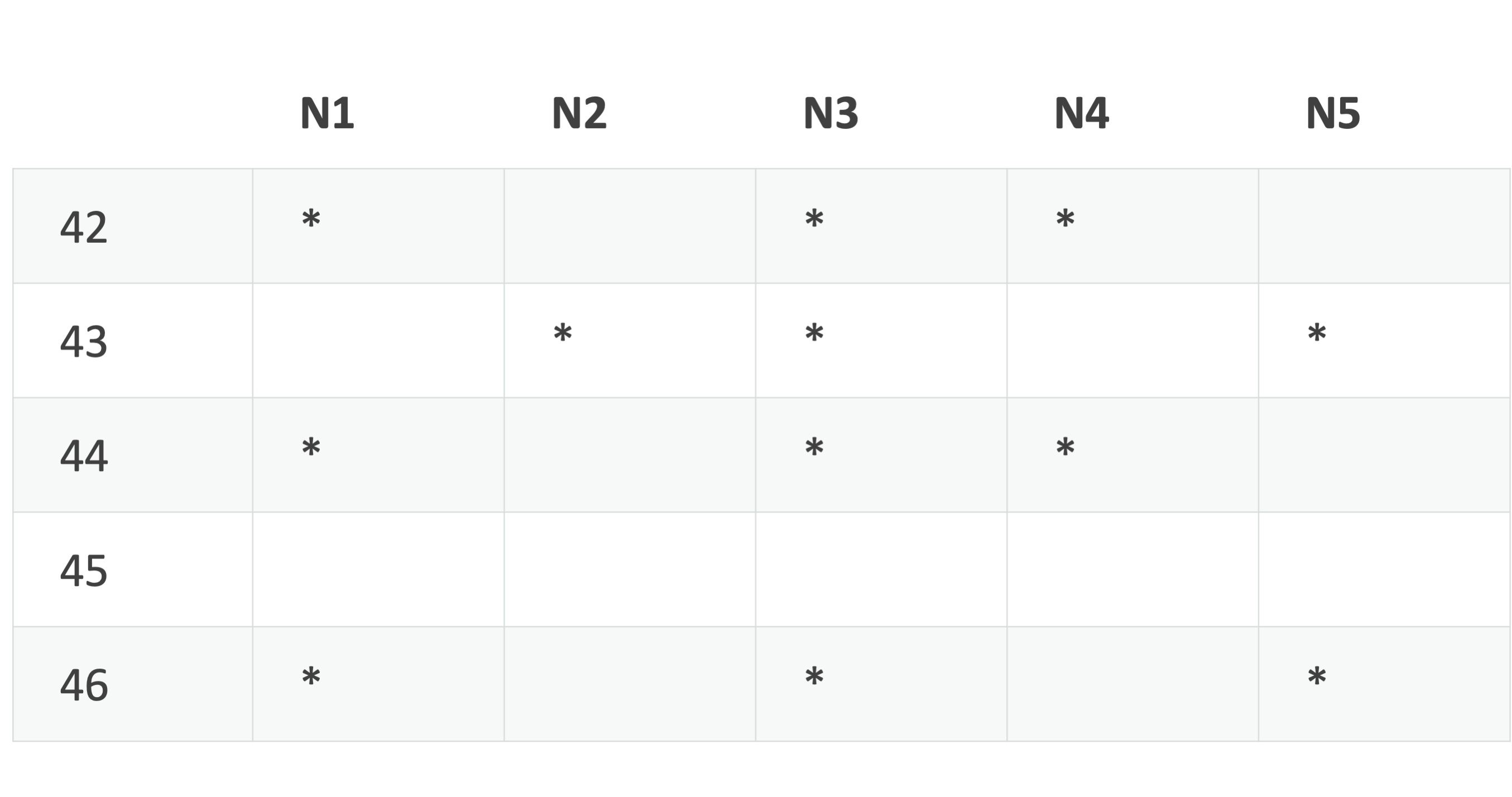
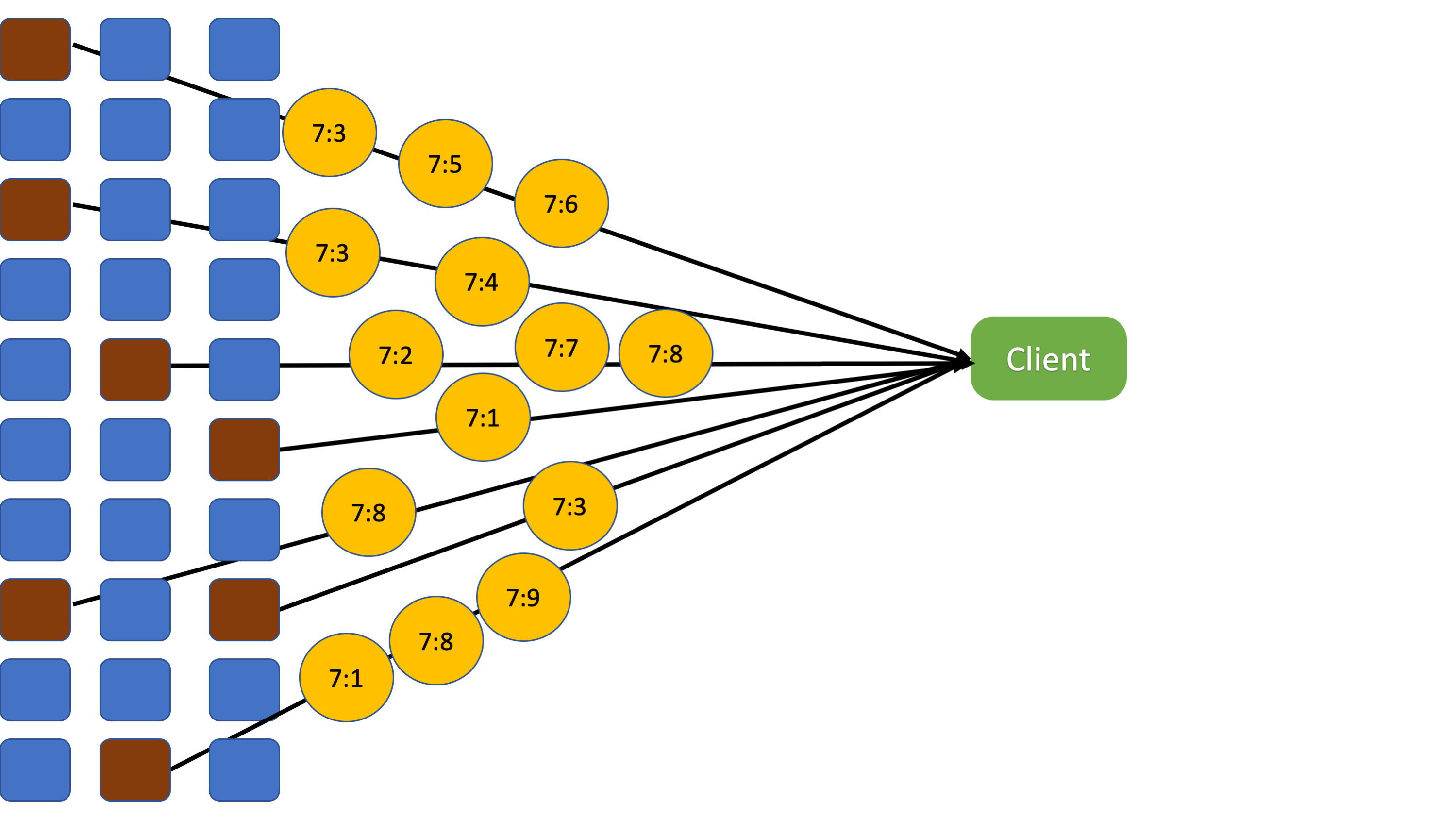
The table represents a client's window with 5 slots and nodes (N1..N5).
- The client asks the storage nodes to send records with sequence numbers 42 to 46.
- As shown in the table, the client received all of the records up to sequence number 44. It delivers one copy of record 42 to 44, in order, to the application.
- The client slides the window so that the first row is for sequence number 45. It sends the storage nodes a window update message asking for sequence numbers 45 to 49.
Gap detection
Most of the time, the stream of records received by the reader is made of continuous sequence numbers, but it's not always the case. Sometimes the reader needs to decide whether it must stall and wait for more record copies to be delivered to it by the nodes in the nodeset, or if it can correctly report a record as irretrievably lost and continue deliver subsequent records. This is encapsulated in the gap detection algorithm.
Gap detection algorithm
First, let's review the concept of f-majority, because this concept helps the client determine whether or not data is unavailable. The f-majority can be defined as a set of nodes that intersects every possible copyset. By definition, the complement of the f-majority cannot contain a copy set. Therefore, if the client has responses from an f-majority of nodes in the nodeset, it has enough information to say whether or not data is available for a particular record.
If the client hears from |nodeset|-R+1 nodes, where R is the replication factor, that’s an f-majority. The formula applies to all replication domains. The formula for rack replication is |num_racks|-Rrack+1. If the replication factor across racks is 2 and there are 5 racks, if the client has heard from all of the nodes on 4 racks, it has f-majority. You have f-majority if you have f-majority for any one replication domain.
The gap detection algorithm says that a record for an LSN is considered non-existent if it’s not replicated according to replication constraints. If |nodeset|-R+1 storage nodes tell the reader that they never had a copy for that sequence number, there is no point in asking more storage nodes because there aren't enough of them in the nodeset to replicate the record.
If the client receives records that are larger than the "oldest" LSN that it's waiting for, and there is an f-majority of nodes responding for that LSN, the client declares that record as lost, issues a DATALOSS gap, and moves on. If the client has received older records and does not have an f-majority response, it stalls because it can't definitively say whether or not the record it's waiting for is available from the nodes.
In this example, where R is 3, and the nodeset size is 5, the reader is stalled because it has not received a copy for sequence number 52 and less than 3 nodes have said they don't have the record. There could still be a copy replicated on N1, N2, or N4.
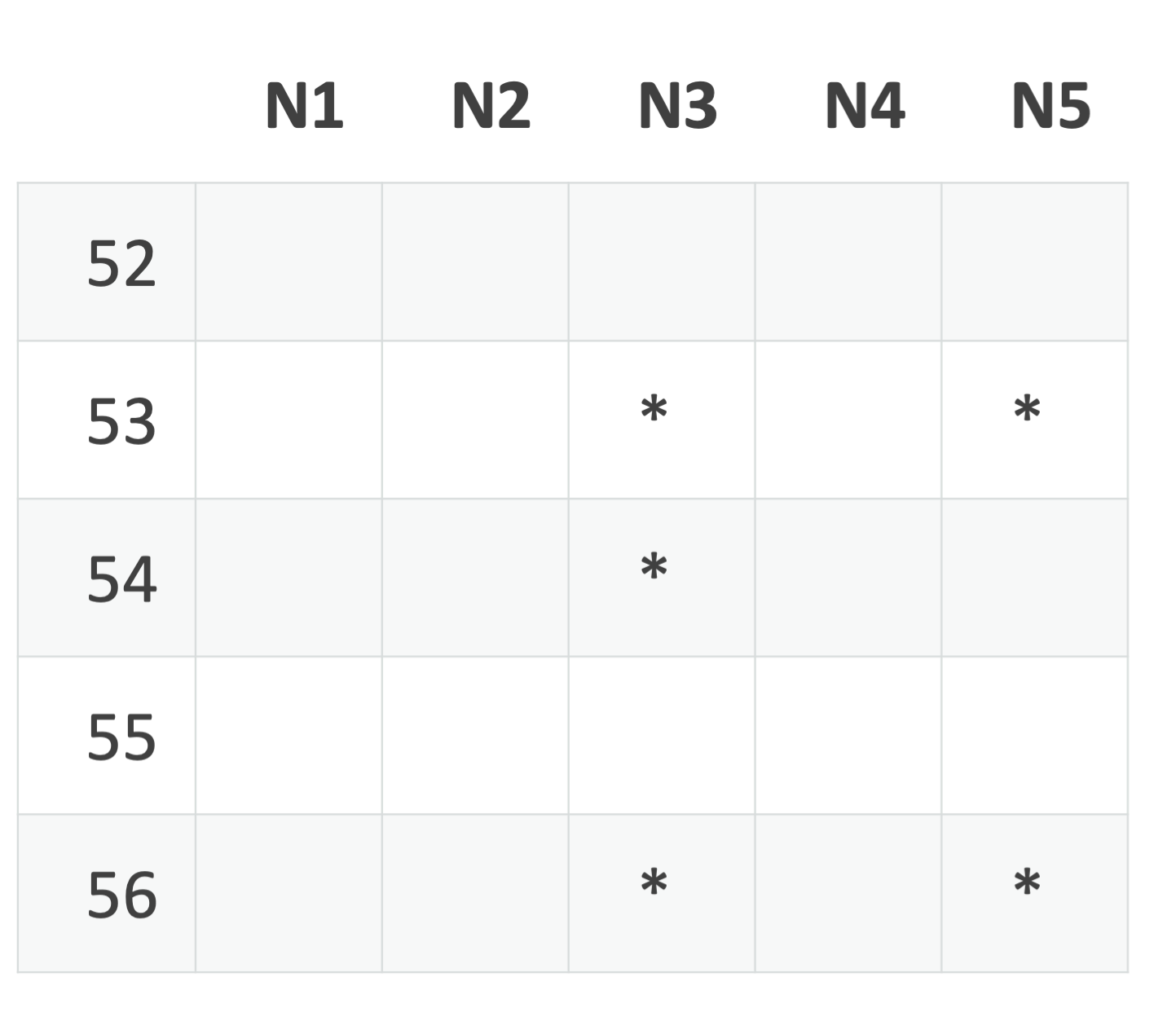
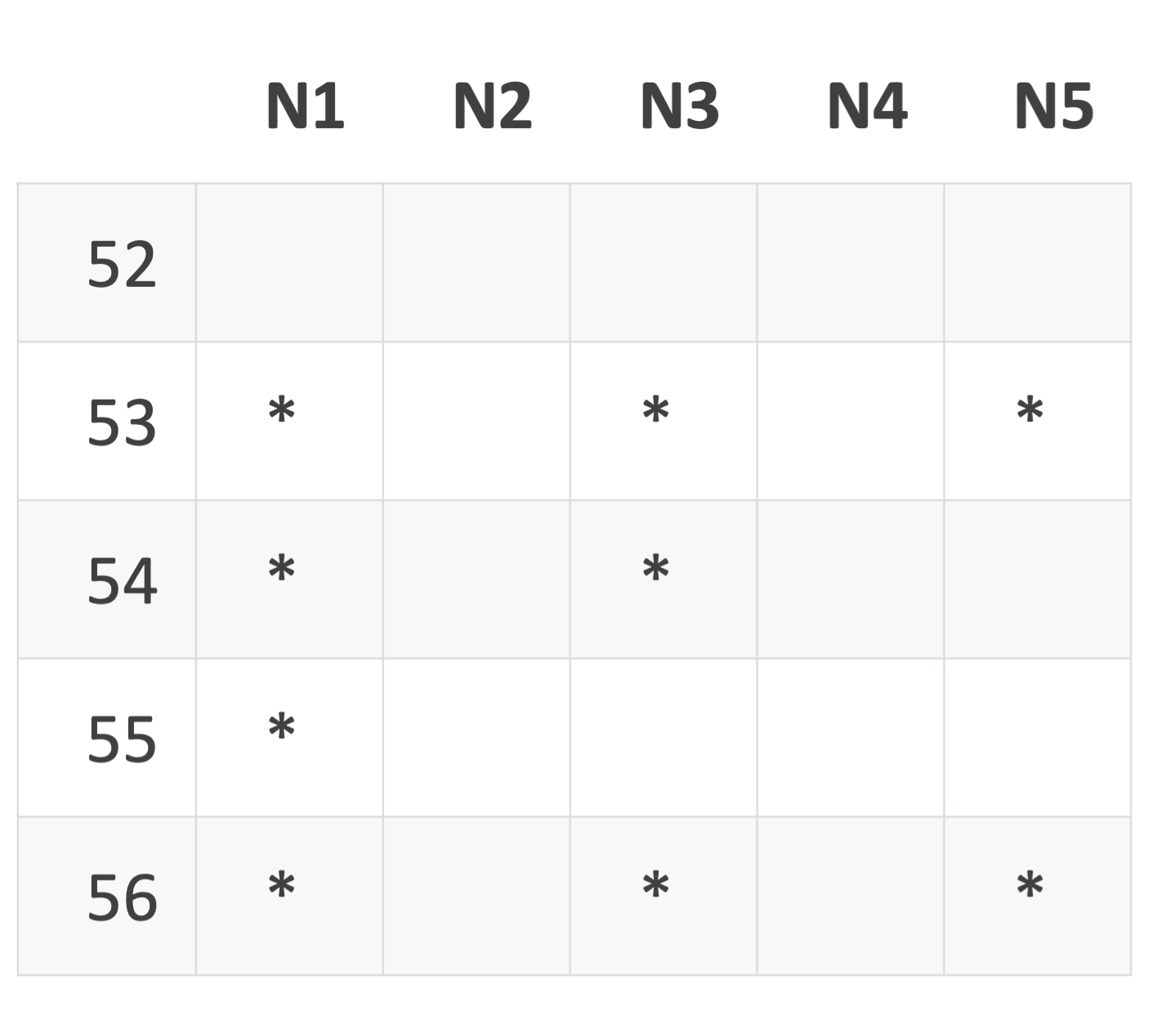
If N1 sends a record with sequence number 54, the client can deduce that N1 does not have sequence number 52 (remember that records are delivered in order by the node). That's enough to conclude there must not be a record for that sequence number. The client issues a DATALOSS for 52 and rotates the buffer so that 53 is the lowest number.
Authoritative Status
Authoritativeness is an extension to f-majority. It considers the effective nodeset of the epoch, taking into account the state of each node in the cluster. For example, the effective nodeset doesn't include nodes that are empty because they have been drained or rebuilt or failed.
Each node has an Authoritative Status that's recorded in the internal event log. Status values are:
- Fully Authoritative: This is the normal state for a node: it has data and should be considered for f-majority.
- Underreplicated (
UNDERREPLICATION): The node is marked unrecoverable in the event log. The data on that node is not coming back. A node is not marked in this way just because it goes down. Its disks are marked unrecoverable only once the node comes back up with disks that have been wiped or replaced, or when the admin manually marks the disk as unrecoverable (ldshellmark-unrecoverablecommand). - Authoritative Empty: The node was down and the records have been copied elsewhere. In production clusters, we always have some storage nodes that are
AUTHORITATIVE_EMPTYbecause they are waiting for faulty hardware to be replaced or because they have been drained (and their data relocated onto other nodes) for later decommissioning. - Unavailable: The node is down.
Once we consider authoritativeness, the gap detection algorithm changes a bit. A data loss gap can be issued if:
- An f-majority of
FULLY_AUTHORITATIVEnodes said they don't have the record, OR - We don't have an f-majority but all nodes that are
FULLY_AUTHORITATIVEsaid they don't have the record. For example, if all the storage nodes that the reader is not able to talk to are markedUNDERREPLICATION, the reader is allowed to issue a gap even though it does not have an f-majority.
For example, consider a nodeset with 7 nodes (N1..N7) and one of them, N5, is down. Rebuilding occurs, and everything that was stored on N5 is replicated onto other nodes in the nodeset. In this case:
- We can treat
N5as if it was never in the nodeset. The effective nodeset only contains 6 nodes. - We mark
N5AUTHORITATIVE_EMPTY. - During rebuilding, all of the copysets are updated for all the copies of each record that was housed on
N5.N5is removed from the copyset and the new location of the replica is added.
Gaps sent by storage nodes
The discussion so far assumes that storage nodes only send records. However, a storage node can send a gap message that explicitly indicates that it does not have records for a range of sequence numbers. Some of the cases when this happens:
- The storage node caught up to the tail of the log.
- The next record to read is outside of the sliding window.
- The next record could not be read in the current batch, and the storage node has to perform another read. A batch is a unit of reads performed by a storage node. The storage node “closes a batch” by sending an explicit gap message.
Knowing that storage nodes also send gap messages, the rule for issuing a data loss gap to the application can be updated again. The client can issue a data loss gap if:
- An f-majority of
FULLY_AUTHORITATIVEnodes sent a record or gap with a higher sequence number, OR - It doesn't have an f-majority but all nodes that are
FULLY_AUTHORITATIVEsent a record or gap with a higher sequence number.
Reporting gaps to the application
The gap message issued by a storage node to the client reader is a NO_RECORDS gap. If an f-majority of nodes send a NO_RECORDS gap, the reader issues a DATALOSS gap to the application.
The client reader reports both benign gaps and data loss to the application through the gap_out parameter of the read API. Benign gaps include bridge records and hole plugs:
- The bridge record is written at the end of every epoch.
- The hole plug is written by the recovery process to indicate that there is no data for this LSN, and the writer did not get an ACK for it.
Optimizations
We have added some optimizations to the read path to increase efficiency. These include compression, sticky copysets, copyset indices, and single copy delivery.
Compression
Payload data is compressed using zstd compression. The client expands the payload before passing it to the application.
Sticky copysets
In order to improve batching, the sequencer may continue to use the same copyset for a large number of consecutive records in the log, as long as the writes on the copyset successfully complete. This technique is called sticky copysets. It effectively groups records on storage nodes in large variable size blocks.
For more about sticky copysets, see Write path.
Copyset index
As another optimization, each storage node maintains a copyset index that contains the LSN of each record stored on the node and its copyset. The index is updated as new records arrive and old records are trimmed.
The storage nodes leverage the copyset index to efficiently filter each record. When the index is combined with sticky copysets, where same copyset is used for multi-megabyte blocks of consecutive records, efficiency goes way up: the filtering decision applies to a whole block which is either read and delivered, or skipped.
Single copy delivery
To avoid reading and sending each record multiple times, single copy delivery (SCD) provides a consistent way of selecting one node in the copyset to read and deliver a copy of each record.
Every storage node that has a copy of a record also has its copyset, so it knows which other nodes also have that copy. Each storage node in the copyset deterministically shuffles the copyset of each record using a seed that is sent by the client. Only the storage node that appears first in that shuffled copyset sends a copy.
There are a couple of variations:
- Local SCD (experimental-only feature). The client sends its location, and then only one node from the same region supplies the record.
- If shuffle mode is turned off, then the first node in the copyset sends the record.
- Fixed seed. This option means all readers are served any given record by the same node. This increases read performance if you have multiple clients reading around the same spot in the log.
SCD is set via the scd-enabled log attribute. Local SCD is set via the local-scd-enabled log attribute. See Log configuration.
For the other two modes, see scd-copyset-reordering-max in Configuration settings.
Known down list
Clients start reading from a storage node by sending a START message to the nodes in the nodeset. In this message, the flag SINGLE_COPY_DELIVERY defines if the created read stream uses SCD. If the flag is set, the START message also contains a list of nodes — the "known down list" — that are considered down by the client.
The storage nodes take the copyset for the record, remove any entries from the known down list, and then apply the shuffle algorithm to figure out which node should send the next record.
Usually a storage node is added to the known down list because the client couldn't connect to it or initiate the streaming protocol because the node is down or underreplicated. If a node has lost its data or can't deliver records for some other reason, it'll tell the client during the handshake.
If a node sees itself in the known down list, and it's able to send records, it sends them as if it wasn't in the list. Each time the client slides the window, it checks to see if any of the nodes in the known down list have sent records. If so, the client removes them from the list and rewinds the stream.
Rewind
A stream is "rewound" if the client decides to send another START with a start_lsn smaller or equal to the read pointer of that stream. The client rewinds the stream when it modifies the known down list or when it switches between SCD and non-SCD mode.
All Send All (non-SCD) mode
If a client detects a gap while reading in SCD mode, then it:
- Drops everything in the current buffer.
- Adds the sending node to the known down list.
- Broadcasts the
STARTmessage to all the nodes in the nodeset withALL_SEND_ALL. This turns SCD off and tells all nodes with copies of the requested records to send them.
Performing a rewind causes read amplification, but because nodes don't fail often, in practice it doesn't affect overall performance. As long as no more than R-1 nodes are unavailable, read availability is guaranteed.
The next time the client slides the window, it switches back to SCD mode.
By default, the client never delivers a data loss gap to the application while in SCD mode. Each time there is a possible data loss, it switches to all send all mode.
Related settings:
- To turn off the default SCD rewind behavior, use
read-stream-guaranteed-delivery-efficiency. It tends to deliver gaps more aggressively to avoid rewinds in SCD.
SCD greylisting (detecting slow shards)
Although the read path, as described thus far, is very resilient to node failures (server crashed, power loss, disk failed, loss of network connectivity), it's less resilient to «grey» failures, i.e., nodes running in a degraded state. When single copy delivery is enabled, there's nothing to prevent the slowest node in the log's nodeset being the one sending out the records.
So we added a failure detector to the client to make it resilient to grey failures.
The failure detector keeps track of how long it takes for each storage node to complete the client's read window. The client slides the window when the read pointer is past X% of the current window, where X is defined by the setting client-read-flow-control-threshold. As nodes complete windows, the latency samples are added to a bucketed time series and a moving average per node is calculated.
Nodes that are observed to be much slower than their peers are put in the known down list. They are reinstated after a probation period and measured again. Depending on their performance, they are re-added to the known down list for either increasingly longer or shorter time periods.
Related settings:
reader-slow-shards-detection- turn the failure detector on or off