Recovery after the failure of a sequencer
When a node that has the sequencer role becomes unavailable due to a system crash, network partition or other event, the recovery process starts. There are two main components:
- Sequencer Activation. A new sequencer on a healthy node is activated. It creates a new epoch and starts taking writes for the log.
- Log Recovery. The new sequencer starts a procedure called log recovery on the previous epoch.
Sequencer activation
When a sequencer running on a node becomes unavailable, the failure or partition is detected and propagated by the failure detectors that are running on the other nodes. The append for the log is routed to a healthy node and it activates a sequencer.
When the sequencer activates, it requests an epoch number from the epoch store. It can immediately start taking appends in the new epoch so that there is minimal disruption in write availability, usually less than a second.
The sequencer can't release these records for delivery to log readers immediately. This is because records near the tail of the previous epoch, corresponding to in-flight appends at the time of the sequencer failure, might be left with an inconsistent state on storage nodes. Delivering these records as-is would violate LogDevice's repeatable read consistency guarantee.
Instead, the new sequencer starts log recovery. It repairs the sequence of records for the previous epoch into a consistent and immutable state on storage nodes. As soon as log recovery is completed, the sequencer advances the accumulative release pointer of the log to the “last known good” LSN in its current epoch. This allows all records up to the release pointer be delivered to existing readers with repeatable read guarantees.
Log recovery
The goal of log recovery is to achieve durability, consistency, and immutability for the strand of records up to the end of epoch affected by the sequencer failure. More specifically, for a successfully recovered epoch:
- All records that were previously acknowledged to the writer must be durably stored, satisfying the replication property of the epoch, and always be delivered to the reader.
- LSNs with missing records caused by unfinished appends that did not get acknowledged to the writer should never be reported as data loss to readers. Instead, they are identified as “benign gaps” in the LSN sequence.
- Once recovered, the content of the epoch must stay immutable until being trimmed. This remains true even in situations like a sequencer in the previous epoch is still alive and taking writes, or there are log recovery attempts by other sequencers.
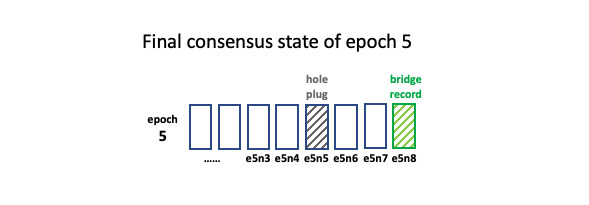
Bridge record
A bridge record is stored by the log recovery procedure at the end of a recovered epoch. It is a regular log record but with a special internal type. Its sequence number represents the consensus about where the epoch ends that was reached by nodes that participated in the recovery. It tells readers to advance the epoch through a benign bridge gap (i.e., no data loss).
Recovery example
Let's look at an example of a sequencer failure and recovery.
Here we have a normal state: the sequencer is writing to 5 storage nodes (N1-N5), with only one record (e5n6) ACKed since the last known good LSN. The replication factor is 3, and some records have not been fully replicated yet.
 Both the sequencer and storage node N1 go down.
Both the sequencer and storage node N1 go down.
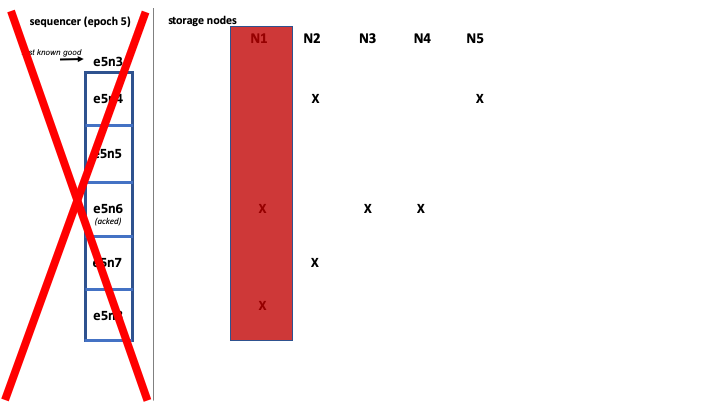
A new sequencer activates and immediately starts taking appends in the new epoch e6, but it can't advance the last known good pointer for the log just yet. Updating the pointer at this time could pose some problems:
- It breaks the replication property for the log if the records are underreplicated.
- A "hole" in the numbering sequence produced by an appender that failed before storing any copies of its record, such as e5n5, may be mistakenly reported as data loss to the readers. This gap does not constitute data loss because LogDevice promises the delivery of only those records which were positively acknowledged to their writers.
- If the other storage nodes in this scenario are unaffected, they might eventually store the in-flight appends. Client readers could see different views of the stored records depending on when they read which violates the LogDevice consistency guarantee.
The new sequencer starts the log recovery procedure:
- It tells the storage nodes in the nodeset of the epoch to reject records with epochs smaller than e6. This prevents an old sequencer, if it exists, from completing any new append.
- It looks at the records in the previous epoch that are later than the last known good pointer, and proposes the outcome for each LSN slot. The outcome is either a record (if one can be found) or a hole plug based on the read result. For a previously ACKed LSN slot, the sequencer always proposes a record.
- It replicates the outcome to the correct number of nodes.
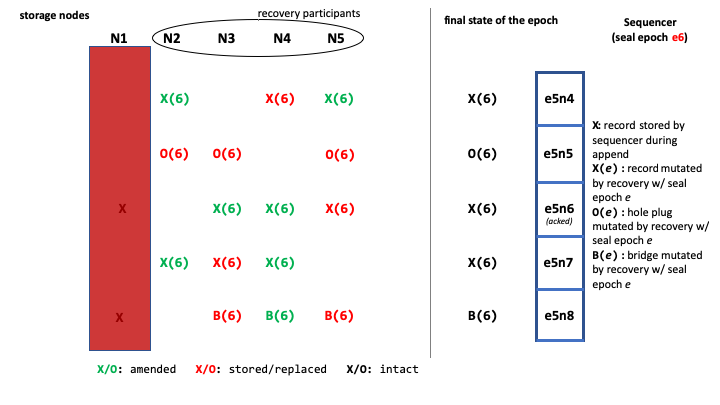
Final state after recovery is complete
When log recovery is done:
- No further appends may succeed in epochs smaller than e6.
- The record in e5 with the highest LSN (e5n8) is a bridge record.
- Every record in e5 that was not ACKed to its writer is either fully replicated to a valid copyset or is replaced with a hole plug record with the same LSN as the original record.
- All properly replicated records are intact.
- e5 is saved in the epoch store as the last clean epoch of this log.
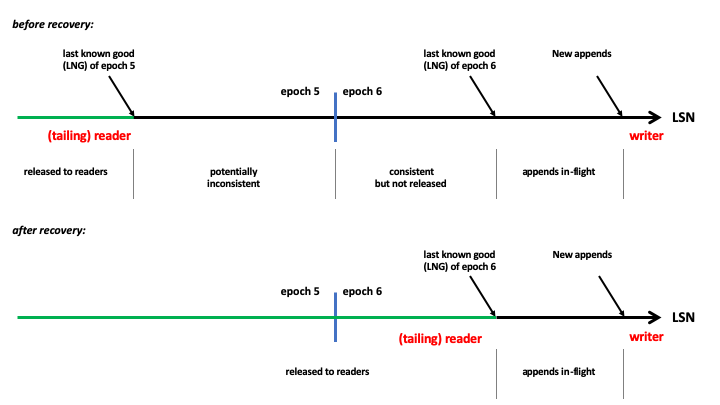
Finally, the sequencer advances the release pointer for the log to the last known good LSN of the current epoch, e6, allowing all records up to the release pointer be delivered to the readers.