LogsDB
The local log store of LogDevice is called LogsDB, which is a layer on top of RocksDB. LogsDB is a time-ordered collection of RocksDB column families, which are full-fledged RocksDB instances that share a common write ahead log, but not memtables or table files.
RocksDB
The three basic constructs of RocksDB are memtables, SST files, and logfiles.
- The memtable is an in-memory data structure. New writes are inserted into the memtable and are optionally written to the logfile.
- The logfile, or write ahead log (WAL), is a sequentially-written file on storage. When the memtable fills up, it's flushed to an SST file on storage, and the corresponding WAL can be safely deleted.
- The data in an SST file is sorted to facilitate easy lookup of keys. SST files are also called L0 files in LogDevice. LogDevice only uses RocksDB L0 (Level 0) files.
As mentioned elsewhere, in LogDevice, regular appends are written to the memtable but not the WAL. Rebuilding appends are written to memtable and WAL.
Shards
RocksDB supports partitioning a database instance into multiple column families. In LogDevice, each RocksDB instance is a shard. A RocksDB column family is a partition in LogDevice.
As far as the LogDevice server is concerned, a shard is one directory. Each RocksDB instance, or shard, shares block cache and the memtable size budget with the other instances on the same node (see Memtable size). Otherwise the RocksDB instances are independent, with their own files and data structures.
Partitions
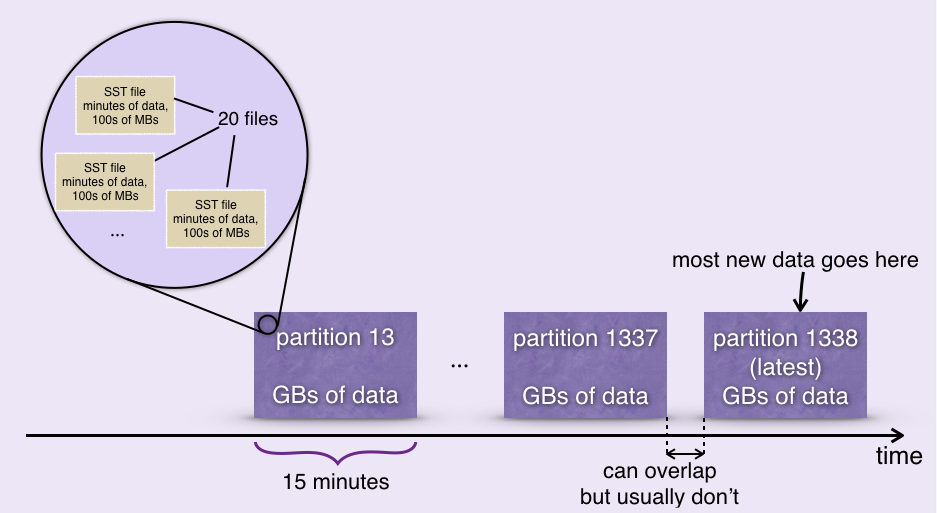
Each shard on each node contains a sequence of partitions. Each partition corresponds to a time range that's a few minutes or tens of minutes long.
All new writes for all logs are ordered by (log id, LSN) and saved on disk in a sequence of large sorted immutable SST files.
Each partition corresponds to a time range and contains all the records with timestamps that fall into that range. The typical length of that range is about 15 minutes and the data size in the partition is a few gigabytes. Typically there are around 20 SST files in each partition. A new partition is created every few minutes to accommodate new data.
Usually newly appended data is written to the latest partition, but all partitions are always writable. In particular, during rebuilding, many records are written to old partitions.
Reading
When reading a log, LogsDB reads the records in each partition in log sequence number order. Read amplification is capped by the maximum number of SST files per partition.
Viewing partitions
If you look at the files in a LogDevice server when it first comes up, you'll see some empty partitions.
`ldshell -c /dev/shm/tmp/logdevice/IntegrationTestUtils.da6c-1b2a-59b9-b0c3/logdevice.conf`
`root> SELECT * FROM partitions`
`root> SELECT node_id,shard,approx_size,l0_files FROM partitions`
Configuring LogsDB and RocksDB
There are many LogsDB and RocksDB settings. The rest of this page describes the settings that you should pay attention to.
Compaction
Compaction reads only those records that are being kept and copies them to new SST files. So if only a small percentage of records are kept, then not much data is read, making this an efficient process. Records that are behind the trim points for the logs are not read.
You can configure a compaction schedule for a cluster using rocksdb-partition-compaction-schedule. The compaction schedule should be aligned with the length of time you want to keep the logs with the highest throughput. There is less benefit in compacting to remove only a small amount of data.
You specify one or more time intervals in a compaction schedule. For example, “3d, 7d” means that each partition is compacted twice. This is a reasonable setting if most of the logs have a retention period of 3 days or less, and most of the remaining logs have a retention of 7 days or less. Supported time intervals are (s, min, h, d, w).
The default value for rocksdb-partition-compaction-schedule, auto, says to use the backlog setting in the config file for the log. backlog specifies the age at which the records of the log can be trimmed.
If all the records in the oldest partition are behind the trim point for their logs, then RocksDB drops the partition.
At Facebook, compaction has proved to be efficient. You could avoid compaction overhead by segregating logs on different clusters according to how long they are to be retained.
Partitions per shard
RocksDB works best if you have less than 2000 partitions in a shard. The setting is rocksdb-partition-count-soft-limit, the default is 2000, and you should leave it at the default.
So that you don't get more than 2000 partitions, you should check these settings, and adjust rocksdb-partition-size-limit if necessary.
rocksdb-partition-duration— Create a new partition when the partition gets this old. Default is 15 minutesrocksdb-partition-size-limit— Create a new partition when the partition reaches this size. Change this setting if necessary (notrocksdb-partition-duration). Default is 6G
Memtable size
The memtable size specified by rocksdb-memtable-size-per-node is divided among the shards. Once exceeded, the oldest memtable in the shard whose growth took the total memory usage over the threshold is automatically flushed. Default is 10G.
Deleting logs
If a log is deleted, all the log's data is kept for rocksdb-unconfigured-log-trimming-grace-period, default 4 days, after it was removed from the configuration. The data is kept in case the log was deleted unintentionally. Trimming of the log is disabled for the configured number of days, and then all the data is removed at once.
See also: Removing Logs.
RocksDB block size and cache size
You should review these settings:
rocksdb-block-size— Default is 500K, big enough for HDD. May make sense to decrease on flash. The main consideration is that the rocksdb index takes ~50 bytes per block, and that the rocksdb index for all open files (rocksdb-max-open-fileslimits that) is kept in memory.rocksdb-cache-size— Default is 10 GB. Size of uncompressed RocksDB block cache. When RocksDB reads an SST file, it reads a block at a time.
Partial compactions
Sometimes, as a result of rebuilding, partitions end up with many small SST files. When it detects this, LogsdDB compacts just those files. There are many relevant settings but they have reasonable defaults.
Write ahead log (WAL)
At Facebook, normal (non-rebuilding) appends are not written to RocksDB WAL. The downside is that if a memtable is lost, the system has to do mini-rebuilding to recover the lost data.
If you are not Facebook, you can avoid mini-rebuilding by setting append-store-durability to async-write (the default).
Copyset index (CSI)
If payloads are .5 Kb or larger, you should enable copyset index. The copyset index, which contains only the metadata for the record, is written at the same time as the entire record (metadata and payload). For larger records, checking the copyset index first to decide whether to read the actual record with the payload, saves CPU and IOPS.
These settings are enabled by default:
write-copyset-index(for writing).rocksdb-use-copyset-index(for reading).
If your record payloads are smaller than .5 KB, disable the settings. For example, we have copyset index disabled for 80 byte payloads on flash drives.
Findtime index
If you have a use case where you need to find records frequently based on their exact time, then turn the findtime index on for fastest retrieval. If write-find-time-index is enabled, then for each record written, an index record with timestamp and LSN is also written. Using the index avoids having to do a binary search by sequence number in the partition.
findTime() is an API to locate the LSN of a record that corresponds to a given timestamp. By default, it returns an LSN that approximately corresponds to that time. To find the exact match, use the findTime() API in strict mode.
These settings are disabled by default:
write-find-time-indexrocksdb-read-find-time-index