Traffic shaping
LogDevice can differentiate its outbound network traffic into multiple classes with distinct priorities, minimum guaranteed bandwidth allocations, and bandwidth caps. It can throttle the traffic of one class while another class gets more bandwidth. This ensures that events such as rebuilding don't affect write availability.
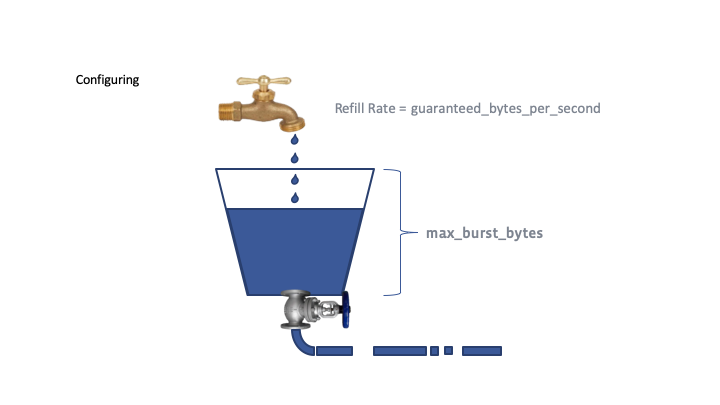
Traffic shaping is a modified version of the token bucket algorithm. Each traffic class is configured with a bucket which represents the maximum network bandwidth that it can use. Every 1 ms, each class is given its deposit of tokens. If the bucket overflows, then the excess is offered to other members of the same class. After the next interval, if that amount has not been consumed, it goes to another bucket called the priority queue.
How traffic shaping works

Each traffic priority level is assigned a bucket, or allocation, of transmission credits measured in bytes. The buckets are sized so that a burst of traffic will not overwhelm the buffering capacity of the network (e.g. in a top-of-rack or cluster switch). As messages are sent, the level in the bucket decreases.
Because of the way that LogDevice shards work across threads, there is one instance of a traffic class's bucket for each shard. These are called traffic class members in this document.
Each time the traffic shaper runs (every 1ms), it deposits the guaranteed bandwidth credits for each traffic class in its bucket. A bucket cannot be filled beyond its capacity so that the configured burst size is honored. If a bucket fills completely, the excess credits are made available to other class members during the next time interval. After that, if there are still excess credits, they are added to a bucket called the priority queue.

The priority queue represents network bandwidth that is not allocated to any class. Each time slice, the priority queue bucket credits are distributed, in priority order, to the classes that have not filled their buckets. If the priority queue bucket overflows, those credits are discarded.
For more details on the design, see Traffic Shaping Design below.
Categorizing traffic
Traffic is classified by the higher level operation that generates the traffic. A client request to add new records to a log is a different class than appends needed to re-replicate data after a failure in a cluster.
Traffic classes are listed below with their meanings. These classes are also used for network traffic stats reported via LogDevice's admin interface.
| TRAFFIC_CLASS | Description |
|---|---|
| APPEND | Adding new records. |
| FAILURE_DETECTOR | Node failure detection. |
| HANDSHAKE | Connection negotiation. |
| TRIM | Explicitly culling old records. |
| READ_TAIL | Reading from in-core log data or marked as a high-priority reader. |
| RSM | Reading or writing Replicated State Machine (RSM) logs. |
| TRIM | Explicitly culling old records. |
| READ_BACKLOG | Reading from disk or explicitly marked as a low-priority reader. |
| REBUILD | Reading or writing a record to restore its replication factor after a failure. |
| RECOVERY | Sequencer recovery and purging of unclean epochs. |
Traffic priorities

Each traffic class is assigned a single transmission priority. Using the same traffic class for all messages related to a single higher level operation guarantees that these messages are dispatched in FIFO order.
LogDevice maps traffic class to priority as follows:
| PRIORITY | Description | TRAFFIC_CLASS |
|---|---|---|
| MAX | Highest possible priority. Use rarely, such as when a client's priority isn't yet known, or for operations whose completion blocks read or write availability. | HANDSHAKE, FAILURE_DETECTOR, RECOVERY, RSM |
| CLIENT_HIGH | Realtime client priority. | APPEND, TRIM |
| CLIENT_NORMAL | Default client priority. | READ_TAIL |
| CLIENT_LOW | Best effort client priority (such as a batch backlog reader). | READ_BACKLOG |
| BACKGROUND | Operations that should have minimal impact on response times to normal client traffic. | REBUILD |
| IDLE | Only run if nothing else can. Reserved, not currently used. |
LogDevice is optimized for write availability. So, for example:
- Recovery reads must be performed at high priority. In order to recover from a sequencer failure, LogDevice must read the last portion of a log before new writes can be processed for that log.
- Rebuilding reads intended to restore the replication factor for a log after a drive or node failure are less important. They shouldn't interfere with the SLA for client writes and most client reads.
Configuration
Configure traffic shaping via the optional traffic_shaping section in the cluster configuration file.
For each traffic class, you can assign, on the basis of location scope (node, rack, or region) and priority, the following values:
- minimum guaranteed bytes per second.
- maximum bytes per second.
- maximum burst bytes.
The top level of traffic_shaping supports two fields:
default_read_traffic_class- This traffic class is assigned to all client readers by default. To override this, add an entry for the client in the
principalssection.
- This traffic class is assigned to all client readers by default. To override this, add an entry for the client in the
scopes- Each element of
scopescan be individually enabled or disabled. noderefers to communication within the node, such as a sequencer storing to itself. Typically this is not controlled by traffic shaping.- An optional array of
metersset the bandwidth allocations at each priority level. If ameteris absent, the capacity and bandwidth allocation for the scope default to zero. - Each scope is a flow group that uses the same set of allocations or buckets.
- Each element of
Sample traffic_shaping configuration:
"traffic_shaping": {
"default_read_traffic_class": "READ_TAIL",
"scopes": [
{
"name": "NODE",
"shaping_enabled": false
},
{
"name": "RACK",
"shaping_enabled": false
},
{
"name": "REGION",
"shaping_enabled": true,
"meters": [
{
"name": "PRIORITY_QUEUE",
"guaranteed_bytes_per_second": 58000,
"max_bytes_per_second": 75000,
"max_burst_bytes": 5800
},
{
"name": "MAX",
"guaranteed_bytes_per_second": 2000,
"max_burst_bytes": 200
},
{
"name": "CLIENT_HIGH",
"guaranteed_bytes_per_second": 100000,
"max_burst_bytes": 10000
},
{
"name": "CLIENT_NORMAL",
"guaranteed_bytes_per_second": 50000,
"max_burst_bytes": 5000
},
{
"name": "CLIENT_LOW",
"guaranteed_bytes_per_second": 25000,
"max_burst_bytes": 2500
},
{
"name": "BACKGROUND",
"guaranteed_bytes_per_second": 25000,
"max_burst_bytes": 2000
},
],
}
],
},
The principals sections lets you assign client readers to different traffic classes, thus affecting their relative priorities.
"principals": [
{
"name": "tailer",
"max_read_traffic_class": "READ_TAIL"
},
{
"name": "batch_reader",
"max_read_traffic_class": "READ_BACKLOG",
}
The client identifies its name (e.g., "tailer" or "batch_reader") when it creates the client object: it either passes an SSL certificate that contains the principal, or it passes the name string to the client object.
Choosing bandwidth values
Set the minimum required bandwidth at each priority level to the number needed to meet a given SLA when in a degraded state (e.g., when only 3 top-of-rack egress ports are functioning). Additional bandwidth that can be consumed when the cluster is optimal should be added to the PRIORITY_QUEUE bucket. Then, during a sustained outage, you only need to scale back the PRIORITY_QUEUE values, via a config update, in order to adjust for the degraded network capacity.
All settings should be in terms of output for a single node in a cluster.
The total configured burst size of the system is the sum of capacities of all buckets, including the priority queue bucket.
Tuning or making temporary config changes
When tuning traffic shaping, it is often convenient to limit experiments to just a single node. The easiest way to do this is via the admin interface on the node.
Any changes made via the admin interface will be overwritten the next time the node receives a configuration update, even if that update doesn't change the traffic shaping section from the values in the last update.
% traffic_shaping --help
Options error: unrecognised option '--help'
USAGE traffic_shaping [--default_read_traffic_class=NAME][--scope=NAME|ALL [--enable|--disable] [--priority=NAME|ALL [--mbps=<double>] [--max_burst_mb=<double>]]]
END
% traffic_shaping --default_read_traffic_class=READ_TAIL
traffic_shaping::default_read_traffic_class READ_BACKLOG => READ_TAIL
END
% traffic_shaping --scope=REGION --disable
traffic_shaping::REGION enabled => disabled
END
% traffic_shaping --scope=REGION --priority=ALL --mbps=100
traffic_shaping::REGION::MAX::mbps 2.000000 => 100.000000
traffic_shaping::REGION::CLIENT_HIGH::mbps 100.000000 => 100.000000
traffic_shaping::REGION::CLIENT_NORMAL::mbps 50.000000 => 100.000000
traffic_shaping::REGION::CLIENT_LOW::mbps 25.000000 => 100.000000
traffic_shaping::REGION::BACKGROUND::mbps 25.000000 => 100.000000
traffic_shaping::REGION::IDLE::mbps 0.000000 => 100.000000
traffic_shaping::REGION::PRIORITY_QUEUE::mbps 58.000000 => 100.000000
END
Statistics
Several statistics track the behavior of traffic shaping. You can see their definitions in these files:
- /logdevice/common/stats/per_flow_group_stats.inc
- /logdevice/common/stats/per_traffic_class_stats.inc
- /logdevice/common/stats/per_msg_priority_stats.inc
- /logdevice/common/stats/per_message_type_stats.inc
These are visible through the admin interface:
% ladmin --unix-path /dev/shm/tmp/cluster/N0\:1/socket_command
info stats2
or
% ldadmin stats2 | grep flow_group
STAT flow_groups_run_deadline_exceeded 0
STAT flow_group.direct_dispatched.NODE 66
STAT flow_group.deferred.NODE 0
STAT flow_group.discarded.NODE 0
STAT flow_group.cbregistered.NODE 0
STAT flow_group.limit.NODE 0
STAT flow_group.bwdiscarded.NODE 0
STAT flow_group.sent_ok.NODE 85
STAT flow_group.sent_bytes.NODE 6009
...
Histograms showing the latency incurred by traffic shaping are also available:
% stats2 shaping
All Scopes: All Priorities: time_in_queue
< 10 usec : 648 * P50 P75 P95
10..20 usec : 8 * P99
END
% stats2 shaping --scope=REGION
Scope REGION: All Priorities: time_in_queue
< 10 usec : 648 * P50 P75 P95
10..20 usec : 8 * P99
END
% stats2 shaping --scope=REGION --priority=ALL
Scope REGION: Priority MAX: time_in_queue
< 10 usec : 604 * P50 P75 P95
10..20 usec : 8 * P99
Scope REGION: Priority CLIENT_HIGH: time_in_queue
Scope REGION: Priority CLIENT_NORMAL: time_in_queue
< 10 usec : 44 * P50 P75 P95 P99
Scope REGION: Priority CLIENT_LOW: time_in_queue
Scope REGION: Priority BACKGROUND: time_in_queue
Scope REGION: Priority IDLE: time_in_queue
END
% stats2 shaping --scope=ALL --priority=ALL --summary
Name Scope Priority Unit min p50 p75 p95 p99 p99.99 max count mean
------------------------------------------------------------------------------------------------------------------------------------
time_in_queue NODE MAX usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0
time_in_queue NODE CLIENT_HIGH usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0
time_in_queue NODE CLIENT_NORMAL usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0
time_in_queue NODE CLIENT_LOW usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0
time_in_queue NODE BACKGROUND usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0
time_in_queue NODE IDLE usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0
time_in_queue RACK MAX usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0
...
time_in_queue ROW MAX usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0
...
time_in_queue CLUSTER MAX usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0
...
time_in_queue DATA_CENTER MAX usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0
...
time_in_queue DATA_CENTER CLIENT_HIGH usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0
...
time_in_queue REGION MAX usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0 usec 0
...
time_in_queue ROOT MAX usec < 0 usec < 0 usec < 0 usec < 0 usec 16 usec 35 usec 90 usec 907309 3 usec
...
END
% stats2 shaping --scope=RACK --priority=ALL --summary --json
{"rows":[["time_in_queue","RACK","MAX","usec","0","0","0","0","0","0","0","0",null],["time_in_queue","RACK","CLIENT_HIGH","usec","0","0","0","0","0","0","0","0",null],["time_in_queue","RACK","CLIENT_NORMAL","usec","0","0","0","0","0","0","0","0",null],["time_in_queue","RACK","CLIENT_LOW","usec","0","0","0","0","0","0","0","0",null],["time_in_queue","RACK","BACKGROUND","usec","0","0","0","0","0","0","0","0",null],["time_in_queue","RACK","IDLE","usec","0","0","0","0","0","0","0","0",null]],"headers":["Name","Scope","Priority","Unit","min","p50","p75","p95","p99","p99.99","max","count","mean"]}
END
Traffic shaping design
LogDevice employs a variation of the token bucket algorithm for metering traffic at a given priority. In LogDevice's case, however, the bucket analogy isn't perfect. Let's look at how the LogDevice scheme is different.
Really large messages
The maximum message payload size allowed in the system is 32MB. That limit that will only be reached by applications writing log records of that size. Although this should be extremely rare, the traffic shaping system must still allow these messages to pass, even if they exceed the configured maximum burst size. To make this possible, LogDevice will release the next message for a queue being metered by a bucket so long as any credit remains. A message that is larger than the available credit will cause the level to go negative, deferring future transmissions until the level again becomes positive.
Shaping by priority
Each message priority level has an independently operated and configurable bucket which meters the flow of messages at that priority. The priority level specific buckets are the perfect tool for configuring the minimum guaranteed bandwidth and maximum burst size for traffic types of different importance. In most configurations, for example, rebuild traffic must not degrade the performance of normal client activity, but some amount of rebuild activity must be allowed in order to meet a "restoration of replication factor" SLA. The bandwidth necessary to achieve that SLA can be reserved via appropriate tuning of the REBUILD priority's bucket.
The priority queue bucket
The token bucket algorithm on its own has limited support for variable workloads. The capacity of the bucket allows the occasional burst of traffic to be tolerated, but what happens during prolonged periods where the bandwidth for a priority level isn't consumed? This is bandwidth that can and should be used for some beneficial purpose.
LogDevice reclaims this excess capacity and adds it to a special bucket: the priority queue bucket. Same as all other buckets in the system, this bucket has a configurable capacity and refill rate. Unlike the buckets whose overflow feeds into it, when the priority queue bucket overflows, there is no other bucket to catch the discarded credit. This ensures that this "reclamation scheme" doesn't violate the total configured burst size of the system (i.e., the sum of capacities of all buckets, including the priority queue bucket).
Credits are transferred from the priority queue class to other classes, as needed, in priority order.
Controlling memory consumption
There are per-worker and per-process limits on the bytes of pending network messages. This limit is enforced above traffic shaping.
Outbound messages can be deferred for many reasons: a connection may transit a congested hop, a peer may fail leaving a blocked socket until the dropped connection is noticed, or LogDevice may temporarily get "ahead of the network" in processing incoming requests and generating outbound messages. Traffic shaping merely adds another possible reason for messages to be deferred: artificial congestion.
Applying traffic shaping to different resources
Within the LogDevice code base, a collection of buckets, one per priority level plus one for the priority queue, is encapsulated in the FlowMeter class. The combination of a FlowMeter, with the logic for applying configuration and bandwidth updates from the TrafficShaper, makes a FlowGroup.
FlowGroups are so called because they are shared by connections/traffic flows that contend on the same resource. To put this in more concrete terms and since FlowGroups use the same NodeLocationScope definitions used for describing failure domains, look at the definitions in LogDevice/logdevice/include/node_location_scopes.inc.
These scopes correlate to the likely domains that have different levels of network bandwidth.
- When a LogDevice sequencer stores data on its local node (i.e., within the NODE scope), network bandwidth isn't consumed at all, so the messages related to this store shouldn't be limited.
- When a transmission is made to a peer within the same rack (i.e., within the RACK scope), transmission should be limited by top-of-rack switch bandwidth.
- Cluster switch bandwidth will become the dominant limiting factor somewhere within the ROW, CLUSTER, DATA_CENTER, and REGION scopes, depending on the switching topology.
- If a cross region hop is necessary for a connection, the bandwidth limits for cross region traffic can be assigned to the ROOT (logical LogDevice Cluster) scope.
During the establishment of a new connection, LogDevice retrieves information from the cluster configuration and determines the smallest scope that is shared with the peer. This scope information is used to select the FlowGroup that will be used to meter the connection.
While LogDevice creates a FlowGroup for each of the scopes listed above, not all of them are useful for every traffic shaping configuration. By default, only the NODE and ROOT scopes are available for connection assignment. This simplifies the traffic shaping logic since it can assume there will always be some FlowGroup that applies to each new connection. Additional FlowGroups must be present in the cluster configuration for them to be eligible for assignment.
Changing the configured status of a FlowGroup requires a restart of the LogDevice daemon because there is currently no mechanism to dynamically reassign connections to a different FlowGroup.
All FlowGroups default to being disabled. A configured, but disabled FlowGroup will pass all traffic. FlowGroups that are configured can be enabled or disabled dynamically via a configuration update or through the admin interface.
Fairness and independent workers
To avoid contention as much as possible between CPUs, LogDevice employs "worker threads" that operate primarily without reference to global state. The traffic shaping code takes advantage of the existing worker architecture to limit the contention it causes.
Each logical FlowGroup is sharded into per-worker instances. These instances have their capacity and bandwidth allocations scaled accordingly so that the sum of the FlowGroup instances matches the globally defined limits in the configuration. The only cross worker activity occurs when the TrafficShaper deposits credit in and updates the configuration for each FlowGroup instance. This currently happens at 1KHz when traffic shaping is enabled on any scope. If it is not enabled, the TrafficShaper goes to sleep until a configuration change occurs.

When the TrafficShaper visits each FlowGroup instance to deposit credit, it must take steps to ensure that, if sufficient load exists, all bandwidth allocated to a particular scope/priority is consumed by that scope/priority. It must also work to maintain fairness between the independent workers.
To see why this is necessary, consider another rebuild example. In this case, only a single connection is requesting reads for a rebuild operation, and this connection falls on worker 0. This one connection should have access to all of the minimum guaranteed bandwidth allocated to rebuilding for the entire machine. Unfortunately, due to sharding of the FlowGroups, it only has 1/nth (with n being the number of workers). This is an extreme case of load imbalance, but a similar issue occurs any time workers have different amounts of work to perform for the same priority level.
Addressing this issue requires some modification to the "reclamation scheme" introduced in the priority queue bucket section. As the TrafficShaper fills buckets with their refill quantum, any overflow is captured in the "current overflow" bucket. This bucket is unique to each scope/priority.

Once all buckets have been serviced, the excess bandwidth is deposited in a first-fit fashion across buckets for that same scope/priority.

Any remaining bandwidth credit is summed across all priorities within a scope and fed on a first-fit basis to the priority queue buckets for that scope. If bandwidth still remains, it is finally discarded.
To ensure fair distribution of "last overflow" credit amongst the workers, the order in which they are processed is randomized each time TrafficShaper is invoked.
Future work
Currently, traffic shaping support uses a static configuration. When faced with an outage that requires a reduction in the total bandwidth expended, the only choice is to push a new config that tunes the cluster lower. Ideally, the traffic shaping logic would be able to detect such an event by seeing a growth in the backlog of messages to send. In response, the excess capacity during normal operations, represented by the settings of the priority queue bucket, would be scaled back until backlog growth stopped.